The other night I was doing some research for an upcoming blog post, and via Google I found some useful newspaper articles published in the ‘Moonee Valley Weekly‘:
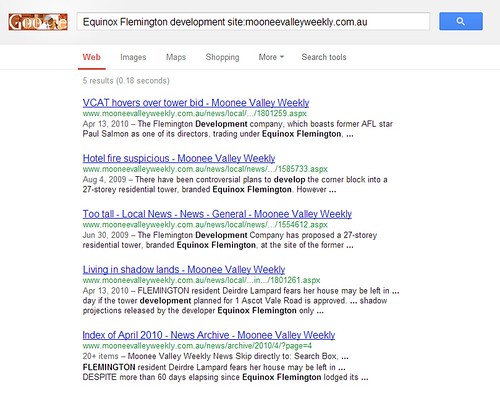
But when I clicked through to each of the links, I ended up at this page:
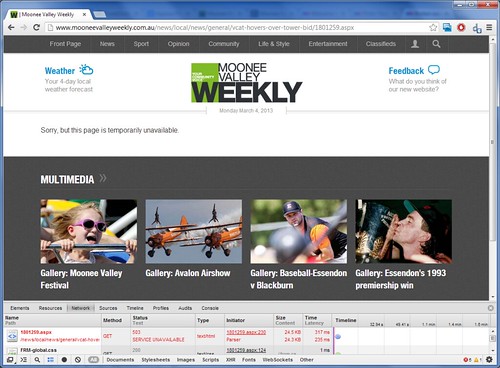
On seeing the error I put on my web developer hat, turned on the Network panel in Google Chrome’s developer tools, and found that in addition to the Sorry, but this page is temporarily unavailable message on the page, the web server was also telling me why it was broken – a HTTP 503 ‘Service Unavailable’ message. Internet standards define this message as the server being currently unavailable because it is overloaded or down for maintenance, and that it is usually a temporary state.
Unfortunately for me the above error wasn’t transient – I have been hitting my head up against the same brick wall when trying to read other online articles from a number of other local newspaper. The common factor – Fairfax. The Moonee Valley Weekly is one of a few dozen local newspapers that form part of the Fairfax ‘Metro Media Publishing’ group, and all of the broken newspaper websites belonged to them.
The root cause of the missing webpages appears to be their website revamp that was launched sometime in August 2012. Here is the homepage of the old version:
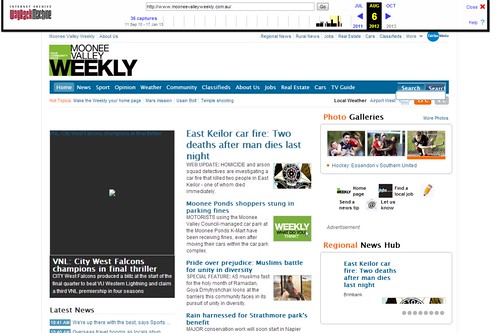
And the new homepage:
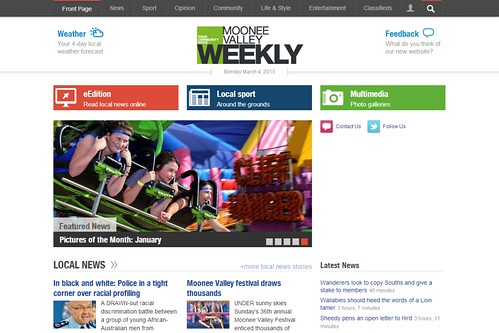
URLs at the old website conformed to this format:
http://www.mooneevalleyweekly.com.au/news/local/news/general/moonee-ponds-shoppers-stung-in-parking-fines/2638396.aspx
While the new URLs are much shorter:
http://www.mooneevalleyweekly.com.au/story/291023/moonee-ponds-shoppers-stung-in-parking-fines/
Note that both of the above URLs include the same random number inside them – 291023 – and that if you enter either into your web browser, you will end up at the same newspaper article – motorists in Moonee Ponds copping parking fines down at their local shopping centre.
If we break down the URLs, with my nerd hat back on I see two things – the ‘random’ number is actually the unique identifier for the newspaper article in the newspaper database, and the rest of the link is just pretty text that makes the URL nicer for humans to understand.
So what has Fairfax gone and done when creating their new website? As well as updating the styling of the website, it also appears they have migrated articles from their old website into a new content management system, and this new system creates links to pages in a new manner. Thankfully Fairfax asked their web developers to add a layer of backwards compatibility so that URLs in the old format are translated to those used in new website, and so ensured that anyone clicking on old links end up at the page they were looking for.
But their mistake? Fairfax missed migrating a big slab of old articles into their new website, but the backwards compatibility logic still attempts to look them up in the new database but fails, resulting in the server crashing, and a HTTP 503 ‘Service Unavailable’ error being presented to the user.
A bonus gotcha arises due to the HTTP 503 error – Google interprets this as a ‘things here are broken, but you can try again later and the website should be back‘ status. This means that for every link that Google has to a Fairfax article that no longer exists, it will continue to be included in the search results – just waiting for the day when Fairfax either makes the article comes back to life, or kills it off for good.

While I am reluctant to complain about what we get for free, I do think there is now some responsibility on organisations to maintain their archives properly.
It is quite a quandary for publishers – in the old days they never had to bother with public archives – we had to rely on local libraries to collect every edition and squirrel them away for us to find. IIRC the big newspapers did have their own archives, but they are pay for access – this is one example:
http://www.newstext.com.au/
Since newspaper articles have become available over the internet things changed – the need to head down to the library to find something from the archives has disappeared. Given how hard things used to be, I guess we can’t be too hard on publishers.
(but still, the difference in effort between migrating just some of the articles vs. migrating all of them is trivial)
The wonders of automated content migration. If they had put their hand in their pocket and paid for someone to do it manually this wouldn’t have happened.
Ugh, I hate when people do migrations to new sites and don’t add 301 redirects for their old URLs. It would have been incredibly simple to write a rewrite rule for the old URLs 🙁
Hi all,
For those wondering why the 503s are still there, here is a brief overview:
The migration of 180+ publications to a new platform has been a huge task, covering hundreds of thousands of articles and terabytes worth of media. This project started last August/September.
The migration of archives was paused for a while as we built in support for a scalable media backend solution (i.e. images stored across multiple cloud regions). Note: there were a number of reasons why we didn’t take the easy route by adding extra HDDs to the media servers; I won’t go into these here.
As you would be aware, 404s and 301s aren’t appropriate if you would like the Google Bot to keep revisiting old URLs in Google’s index – 503s are the recommended status code.
I’m happy to say that the scalable storage solution goes live this week, which means that the archives can come across in the next week or two.
301 redirects will kick in automatically and there should not be any issues accessing them.
Thanks,
Ian
Product Technology Mgr, Fairfax Media
Ian, thanks for the rundown of the migration. I can see why migrating terabytes of data that is accessible via the web is a lot more difficult that just throwing a new hard drive into my home computer and doing a copy paste.
And it is good to head that the archives will be back once the work is complete. Dealing with such a long tail of old articles sure complicates matters.
[…] I touched on the issue of website migrations leaving a legacy of broken links a few months ago, when I encountered a similar issue with the Fairfax