While doing some online research research I found evidence of some new functionality in Google Image Search – when crawling the web, Google is applying OCR (Optical Character Recognition) to the images that it finds, and uses this data in their search index.
I was writing a post about the use of antimacassars onboard V/Line trains, so started researching the Australian supplier of the seat headrest covers.

My search term in Google was ‘merino headrex’, which only brought one relevant search result: a copyright application for the ‘Headrex’ name by Encore Tissue (Aust) Pty Ltd, owner of the ‘Merino’ brand.

Bing Search also delivered similar results for the same search query.
But when I flicked over to Google Image Search, something new appeared.

A photo of mine, that was what let me to search for ‘merino headrex’ in the first place.

But the spooky part – I had never put the words ‘merino’ or ‘headrex’ anywhere on my website.
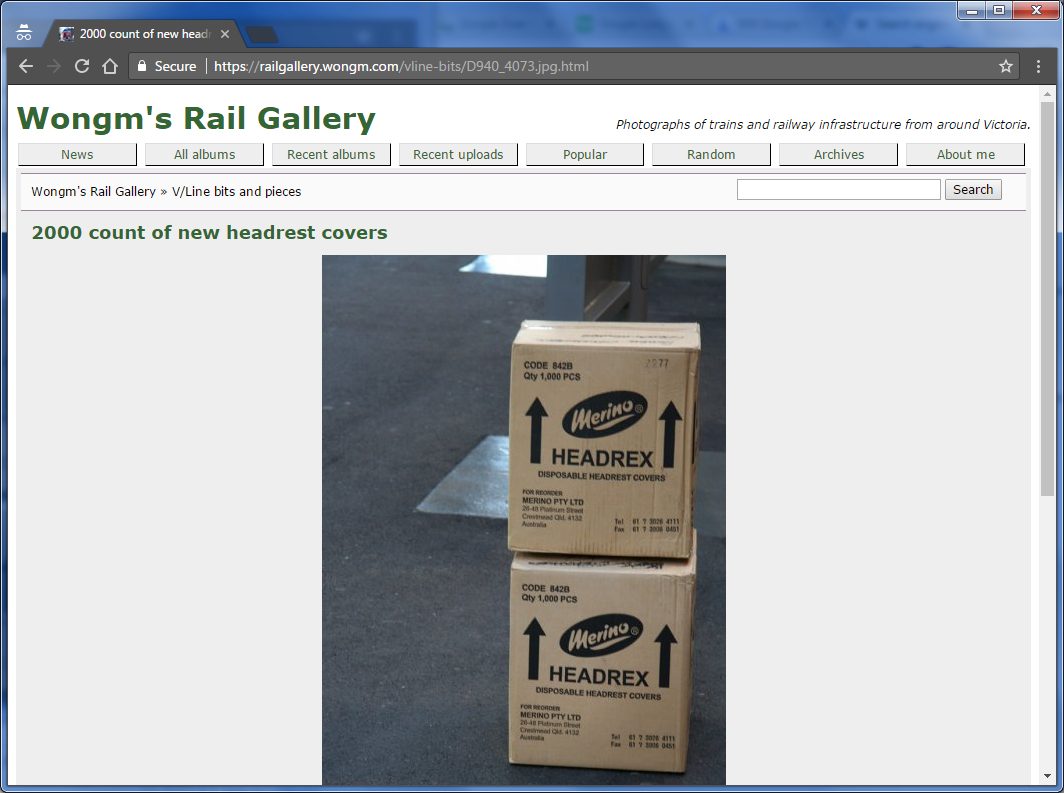
So the most likely explanation – Google is applying OCR to the images that it finds, then adds the data to their search index.
More on Google and OCR
Over the years a number of Search Engine Optimization (SEO) blogs have speculated around Google’s search indexing capabilities.
From TechCrunch in January 2008:
A patent application lodged by Google in July 2007 but recently made public seeks to patent a method where by robots (computers) can read and understand text in images and video.
The extension of the application would be that images and video indexed by Google would be searchable by the text located within the image or video itself, a big step forward in indexing that has not previously been available.
Information Week suggests that privacy issues raised by Google Maps Street View will get more complicated as eventually YouTube videos will be indexable via the text that appears within them.
‘SEO by the Sea’ in November 2015.
I had some hope over the years that Google might get better at indexing text that appeared within links, watching some things like the following happen:
(1) Google acquired Facial and object recognition company Nevenvision in 2006, and a few other companies that can recognize images.
(2) In 2007, Google was granted a patent that used OCR (Optical Character Recognition) to check upon the postal addresses on business listings, to verify those businesses in Google Maps.
(3) Google was granted a similar patent in 2012 that read signs in buildings in Street Views images.
(4) In 2011, Google published a patent application that used a range of recognition features (object, facial, barcodes, landmarks, text, products, named entities) focusing upon searching for and understanding visual queries, which looks like it may have turned into the application for Google Goggles, which came out in September of 2010 – the visual queries patent was filed by Google in August, 2010, the nearness in time with the filing of the patent and the introduction of Google Goggles reinforces the idea that they are related.
But, Googlebot still doesn’t seem to be able to read text in images for purposes of indexing addresses, or to read images of text used in navigation. I added the text “Google Test” to the following image, and then ran it through a reverse image search at Google. The images returned were similar looking, but none of them had anything to do with the text I added to the image.
And ‘Search Engine Roundtable’ in March 2016:
A question was posed to Google’s Gary Illye’s on Twitter if Google’s crawler and indexer understands the text embedded in an image, maybe through OCR or other techniques. I am surprised to hear Gary say no.
@Web4Raw I say no
— Gary Illyes ᕕ( ᐛ )ᕗ (@methode) March 15, 2016
A year is a long time on the internet.
Footnote on Google Image Search for obscure topics
Take a look at the other results from Google Image Search, and spot the odd one out.
My photo of the seat covers, and the Merino sheep make sense. But these three photos…
Railway tracks on a wharf.

People in hi-vis vests standing around a pile of wood.

And a train covered in a tarpaulin.

They have nothing at all to do with a merino sheep, but they do have one thing in common – they are hosted on the same domain as my ‘merino headrex’ image.
Thanks to lack of any other relevant results, Google’s algorithms decided that proximity to a relevant image is enough of a ranking signal to push it up the search result pages.
I’ve confused Google’s algorithms in this way before, with my Hong Kong themed blog at www.checkerboardhill.com/.
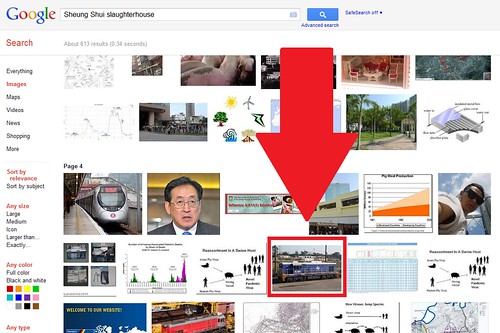
I searched Google for “Sheung Shui slaughterhouse” but was given my own photo of an Australian diesel locomotive!

[…] few years ago I discovered that Google Image Search applies OCR to indexed images, enabling it to return results for text that have never appeared online. Well, now I’ve found […]